Articles
- Page Path
- HOME > J Prev Med Public Health > Volume 51(6); 2018 > Article
-
Original Article
Measuring and Decomposing Socioeconomic Inequalities in Adult Obesity in Western Iran -
Farid Najafi1
 , Yahya Pasdar2, Behrooz Hamzeh1, Satar Rezaei1, Mehdi Moradi Nazar1, Moslem Soofi1
, Yahya Pasdar2, Behrooz Hamzeh1, Satar Rezaei1, Mehdi Moradi Nazar1, Moslem Soofi1 -
Journal of Preventive Medicine and Public Health 2018;51(6):289-297.
DOI: https://doi.org/10.3961/jpmph.18.062
Published online: October 29, 2018
1Research Center for Environmental Determinants of Health, Kermanshah University of Medical Sciences, Kermanshah, Iran
2Department of Nutrition, Faculty of Nutritional Sciences and Food Technology, Kermanshah University of Medical Sciences, Kermanshah, Iran
- Corresponding author: Moslem Soofi, PhD Research Center for Environmental Determinants of Health, Kermanshah University of Medical Sciences, Kermanshah 67198-51351, Iran E-mail: moslemsoofi@yahoo.com
• Received: March 5, 2018 • Accepted: October 11, 2018
Copyright © 2018 The Korean Society for Preventive Medicine
This is an Open Access article distributed under the terms of the Creative Commons Attribution Non-Commercial License (http://creativecommons.org/licenses/by-nc/4.0/) which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.
ABSTRACT
-
Objectives
- Obesity is a considerable and growing public health concern worldwide. The present study aimed to quantify socioeconomic inequalities in adult obesity in western Iran.
-
Methods
- A total of 10 086 participants, aged 35-65 years, from the Ravansar Non-communicable Disease Cohort Study (2014-2016) were included in the study to examine socioeconomic inequalities in obesity. We defined obesity as a body mass index ≥30 kg/m2. The concentration index and concentration curve were used to illustrate and measure wealth-related inequality in obesity. Additionally, we decomposed the concentration index to identify factors that explained wealth-related inequality in obesity.
-
Results
- Overall, the prevalence of obesity in the total sample was 26.7%. The concentration index of obesity was 0.04; indicating that obesity was more concentrated among the rich (p<0.001). Decomposition analysis indicated that wealth, place of residence, and marital status were the main contributors to the observed inequality in obesity.
-
Conclusions
- Socioeconomic-related inequalities in obesity among adults warrant more attention. Policies should be designed to reduce both the prevalence of obesity and inequalities in obesity by focusing on those with higher socioeconomic status, urban residents, and married individuals.
- Obesity is a considerable and growing public health concern worldwide [1-4]. The prevalence of obesity is dramatically increasing in both developing and developed countries [1,5]. Based on World Health Organization (WHO) reports, the worldwide prevalence of obesity doubled between 1980 and 2014. In 2014, over 600 million adults were obese worldwide [6]. Research indicates that some diseases and many undesirable health conditions, such as heart disease, diabetes, and cancers, are attributable to obesity [5,7,8]. Overweight and obesity have been recognized as the fifth leading risk factor of mortality, and at least 2.8 million adult deaths are caused by overweight or obesity annually [9]. Obesity also has significant short- and long-term economic impacts on health services and on nations’ economies, resulting in higher healthcare expenditures, absenteeism, and productivity losses [10-12]. Furthermore, the societal costs of obesity have been estimated to be greater than those attributable to smoking and alcoholism [11,12], and therefore, its negative consequences on countries’ resources are substantial [1].
- Obesity is also a public health concern in Iran. To date, several studies have assessed the prevalence of obesity and its associated factors at both national and subnational levels. They have reported a high prevalence of overweight and obesity in the Iranian population [13-15]. For example, according to the first national survey of weight status in Iranian adults, the ageadjusted prevalence of overweight or obesity was 42.8% in males and 57.0% in females, and 11.1% of males and 25.2% of females were obese [13]. Another study estimated that the prevalence of obesity and the mean body weight index (BMI) in the Iranian population above the age of 18 were 21.7% and 25.2 kg/m2, respectively. That study found an increasing trend in the prevalence of obesity in Iran [15]. The results of an assessment of the prevalence of obesity and its determinants in females residing in Kermanshah showed that the prevalence of overweight or obesity was 39.4 and 21.9%, respectively. That study found lower economic status and illiteracy to be significantly associated with obesity [16]. Recently, a national study based on the Iranian surveillance system for the risk factors of non-communicable diseases reported a prevalence of obesity of 17.5% in Kermanshah in 2005 [17]. Obesity is a complex and multifactorial problem that is affected by factors at both the macro-level (e.g., economic and nutritional transitions) and the individual level (e.g., genetic, psychosocial, lifestyle, and socioeconomic factors) [18]. It should be noted that socioeconomic status (SES) has potential effects on individuals’ lifestyle, eating behaviors, and caloric intake [19,20]. Some ‘unhealthy’ lifestyles and health conditions such as obesity and overweight, particularly in developing countries, tend to be more widespread in specific socioeconomic groups [19-21].
- To the best of our knowledge, there is little information about socioeconomic inequalities in obesity in Iran. To fill this gap in the literature, the present study aimed: (1) to quantify socioeconomic inequalities in the prevalence of obesity in the adult population in Kermanshah, in western Iran and (2) to decompose the observed inequality by quantifying the contribution attributable to each determinant. The findings can help policy-makers design targeted and effective strategies to reduce the prevalence of obesity and socioeconomic inequalities in obesity.
INTRODUCTION
- Study Setting
- This study used data from the Ravansar Non-communicable Cohort Study (RaNCD) study as a regional part of the Prospective Epidemiological Research Studies in Iran (PERSIAN) cohort. The PERSIAN cohort was launched in 2014 and includes 180 000 persons aged 35-70 years from 18 geographically-defined regions of Iran, chosen based on specific characteristics of each region, such as exposure to certain risk factors, local disease patterns and population stability, causes of death, and local commitment and capacity. The PERSIAN cohort was aimed at the identification of the risk factors associated with the most common non-communicable diseases in Iran, with the goal of contributing to evidence-informed policymaking and the world’s medical knowledge. The PERSIAN cohort is turning into a major source of data on Iran’s population, health, nutrition, and lifestyle at the national and subnational levels. To this end, the required data were gathered using an instrument that contained items on many different aspects of life affecting individuals’ health status. Details about the design, sampling, and inclusion and exclusion criteria have been published elsewhere [22]. The city of Ravansar is located in western Iran in close proximity to the Iran-Iraq border, with a population of about 50 000 inhabitants. The majority of residents of Ravansar are of Iranian Kurdish ethnicity. There are 3 urban healthcare centers in Ravansar and 2 other rural healthcare centers, as well as 32 active local health houses (locally known as khaneye behdasht) in rural areas. The RaNCD cohort comprised 10 086 individuals aged 35-65 years old.
- Dependent and Independent Variables
- A dichotomous outcome variable was constructed using the BMI information of samples; in line with the WHO definition, obesity was defined as a BMI equal or greater than 30 kg/m2. Anthropometric parameters were measured using automated bioelectric impedance with integrated automatic stadiometer (InBody 770, BSM350; InBody, Seoul, Korea). The explanatory variables used in the analyses were sex, age, marital status, education, number of members in the household, place of residence, wealth index as an indicator of economic status, and smoking behavior as a lifestyle factor.
- In accordance with previous studies [23-25], SES was classified using data on education level, durable goods, housing characteristics, and other amenities of individuals interviewed in the PERSIAN cohort through applying principal component analysis (PCA). To generate the SES, various factors were considered in the PCA model, such as owning a freezer, a dishwasher, an LCD/LED/plasma TV, a vacuum cleaner, a personal computer/laptop, access to the Internet, a mobile phone, a car, a motorcycle, an extractor fan, a bathroom, access to tap water, the number of rooms for the members of the family, the type of kitchen, the type of house ownership, house area, and the number of foreign and domestic trips. As mentioned previously, education level was included in the PCA model. To perform PCA on the variables related to SES, qualitative categorical variables were re-coded as binary variables. Then, all the variables and other continuous variables were entered into the model. SES was classified by weighting the first factor of PCA [26]. Moreover, the new SES variable were categorized into quintiles to determine the economic status of individuals and were then used in subsequent analyses.
- Statistical Analysis
- The concentration curve (CC) and concentration index (CI) were used, because they are the standard and most frequently-used tools for assessing inequality in the health economics literature [27,28]. The CC is a graphical exhibition of the degree of inequality, which plots the cumulative percentage of the health outcome (y-axis) against the cumulative percentage of the population, ranked by SES from poorest to richest (x-axis). A line of 45° shows perfect equality. If the health outcome variable is concentrated in lower socioeconomic groups, the CC lies above the 45° line (line of perfect equality) and vice versa. The farther the CC is under or above the line of equality, the higher the inequality in the health variable of interest. The CI is directly related to the CC, which quantifies the degree of socioeconomic-related inequality in health outcomes and is defined as twice the space between the CC and the line of perfect equality. This parameter indicates whether the health outcome is concentrated more among people of lower or higher socioeconomic groups. The value of the CI ranges from -1 to +1, and a negative value indicates that the health outcome is more concentrated in groups with lower SES, and vice versa for a positive value. If the CI equals zero, the health outcome is equally distributed among populations [29]. The CI is defined as follows:
- where μ is the mean or the proportion of the health variable and yi and ri represent the variable of interest and fractional rank in the socioeconomic distribution for the ith individual, respectively. Additionally, the individuals were ranked according to their SES, from the richest to the poorest [28,30]. The bounds of the CI for a binary variable are not +1 and -1, and instead depend on the mean (μ) of the variable [28]. To this end, different correction methods were proposed by Wagstaff [28] and Erreygers [31] to address this issue. Hence, according to the results of previous studies [32-34], the method proposed by Wagstaff was employed to normalize the CI. This solution helps to correctly quantify the degree of inequality within the range of -1 to +1. According to the Wagstaff [28] approach, the CI is normalized as follows:
- where μ is the mean of the health variable and CI represents the conventional CI.
- To calculate the contribution of determinants to the inequalities, the Wagstaff-type decomposition analysis of CC was used. This technique is based on regression analysis of the association between the outcome variable and its determinants for any linear additive regression model of health outcome (y), such as:
- The CI for a variable y can be written as follows [25,26].
- Where CI is the overall concentration index, μ indicates the mean of y (health outcome variable),
-
Equation 3 shows that the CI has 2 components: the explained component (
- Since the outcome variable of the present study (obesity) was binary, a non-linear estimation was used. The marginal effects of the βk based on the logic model were estimated, and these marginal effects were then used to compute the contributions of the explanatory variables [30]. Below, the linear approximation of the non-linear estimations is given by equation (5).
- Where
METHODS
Socioeconomic status measure
- Table 1 shows the descriptive characteristics of the sample. A total of 10 086 adults aged 35-65 years, with a mean age of 47.23±8.21 years, were included in the study, of whom 5300 (52.5%) were female. Most participants were 35-44 years old (43.4%), and the majority of the sample was married (90.1%). Furthermore, literate subjects accounted for 54.1% of the sample under study (Table 1), and the overall prevalence of obesity in the total sample was 26.72%. Participants aged 45-54 years old, urban participants, illiterate subjects, and well-off people had higher proportions of obesity than their counterparts. Additionally, 29.09% of the participants in the highest wealth quintile, 36.26% of females, 31.34% of illiterates, and 30.16% of urban individuals were obese (Table 1).
- The normalized CIs are presented in Table 2. The normalized CI was 0.04 for the entire population, 0.10 for males, and 0.11 for females. The positive value indicates that wealthy individuals had a higher rate of obesity than those with lower economic status. As shown in Table 2, the magnitude and sign of the inequality were statistically significant (p=0.002).
- As shown in Figure 1, the CC of obesity lay below the perfect equality line, an indication that the prevalence of obesity was higher among the rich.
- In Table 3, the results of the decomposition analysis are presented, and the contribution of each explanatory variable to the socioeconomic inequality in obesity is explained.
- The contributions come from both the distribution of a given variable across socioeconomic groups (CI) and the elasticity of the outcome variable with respect to the determinants. Elasticity is the responsiveness of the health outcome to a determinant, and is defined as the change in the health outcome in response to the corresponding change (1 unit) in the determinant [36]. A positive contribution means that the combined marginal effect of the determinant and its distribution in respect to wealth increases the socioeconomic inequality in the health outcome, and vice versa for a negative contribution. Thus, if economic status made no contribution, the extent of inequality in obesity would be lower, with other conditions remaining constant.
- As shown in Table 3, living in urban areas and marriage had positive CI values, suggesting that these factors were concentrated among wealthy people. In contrast, being female and smoking habits had negative CI values, indicating that these factors were concentrated among economically disadvantaged people.
- According to the decomposition analysis, female made a negative contribution. If a factor makes a negative contribution, the degree of the inequality in obesity would be higher in the absence of that factor.
- The results indicated that the largest contributor to the CI for obesity was SES, with a positive contribution of 59.2%. Urban residence was the second largest contributor, with a positive contribution of 21.0%, and marital status was also a major contributor to inequality. Household size and age group were the next largest contributors, in order. The contribution of smoking was close to zero because it was equally distributed across socioeconomic groups [35].
RESULTS
- The present study aimed to quantify and decompose socioeconomic inequalities in adult obesity in Iran. The results of the present study revealed a pro-poor inequality (i.e., a positive CI), suggesting that obesity was concentrated among individuals with higher SES. This finding is contrary to a previous study performed in Iran by Emamian et al. [17], in which a prorich inequality in obesity was reported.
- However, our findings are consistent with the results of several other previous studies. For instance, the results of a study on income-related inequalities in obesity risk in Canada found that obesity was concentrated in wealthy people [2]. Similarly, Ljungvall and Gerdtham [37] found that obesity was concentrated among people of higher economic status in Sweden. Furthermore, a study that measured socioeconomic inequalities in adult obesity prevalence in South Africa showed that obesity was more concentrated among wealthy individuals [1]. Another study that measured income-related inequalities in obesity in 10 European countries revealed that income-related inequalities were more concentrated in females of lower SES [20]. To diminish the existing inequalities, a main step in designing policy interventions is to identify the contributors of inequalities in obesity across various populations [38]. Moreover, the results of a decomposition analysis suggested that SES was the main factor that could explain the largest proportion of inequality in obesity. The explanatory variables that made the next largest contributions to the socioeconomic inequality in obesity were urban residence and marital status, in order.
- These results of the present study are consistent with the findings of the previously-mentioned study conducted in Iran, in which females and urban residents made a greater contribution to the inequality in obesity among different SES groups [17]. These findings are also in accord with those of other previous studies. The results of decomposing the socioeconomic inequality in obesity in South Africa also showed that the wealth index significantly and positively contributed to the inequality in obesity. In addition, it was found that educational attainment was a major contributor to obesity [1]. Similarly, demographic variables such as income and education were the main factors that explained the income-related inequality in obesity risk in Canada [2]. According to the decomposition analysis of obesity inequality in Sweden, income was the main driving force behind obesity inequality, whereas being single was an important counteracting factor, and the contribution of age was generally significant [37]. Additionally, education and demographic factors were found to be some of the key contributors to inequalities in obesity in Spain [19].
- In contrast to the previous study in Iran, it was observed that there was pro-poor inequality in obesity in the population under study. A possible explanation for this might be that developing countries have experienced significant social and economic transformations in their epidemiological and demographic structures. Therefore, the socioeconomic distribution of health outcomes has changed in ways that have produced inequalities in health worldwide [39]. It should be noted that the previous study analyzed data from Iran’s surveillance system for risk factors of non-communicable diseases that were collected in 2005 [17]. Therefore, further studies (at the national or subnational level) are required to reach firmer conclusions and to better understand the nature of obesity distribution patterns in Iran.
- The results of the decomposition technique draw attention to the importance of considering these factors and may help with planning and designing interventions to reduce the prevalence of socioeconomic inequalities in obesity.
- The PERSIAN cohort used a rigorous methodology, with continuing supervision and standardized parameters, which may be a strong point of this study. Additionally, data on durable assets and housing characteristics were used to measure economic status (wealth index) because data on income, expenditures, and/or consumption in low- and middle-income countries are often unavailable or unreliable [26]. The wealth index generated by PCA is a reasonable proxy of economic position [1,26]. A combination of durable assets and housing characteristics is an accurate technique to develop the wealth index using the PCA method, leading to fewer limitations in comparison to measures of income and/or expenditures/consumption in developing countries [40]. Nonetheless, the present study was faced with some limitations. First, since the present study was cross-sectional, the results did not show causality. Therefore, a longitudinal dataset would be required to examine the changes in inequality and to make judgments about causality. In addition, this study only included individuals aged 35-65 years because considering the entire age range was not feasible.
- Furthermore, extreme caution should be exercised when generalizing the findings of the present study to other groups. Since smoking was expected to be endogenous in relation to obesity and may lead to potential bias, it was initially excluded from the model used in the decomposition analysis. The sign and magnitude of the contributions of other explanatory variables did not change, and therefore this factor was included in the model, since smoking has been associated with obesity [1]. Furthermore, as the decomposition technique is a deterministic approach, there might have been other factors that were not included in the analytical model and might have contributed to inequalities in obesity [38].
- In conclusion, the results of the present study demonstrated that there was a pro-poor inequality in obesity in the population under study. The results also suggested that a substantial fraction of the inequality in adult obesity was explained by SES, followed by urban residence and marriage. Thus, to reduce the prevalence of obesity and inequality in obesity, intervention policies should be focused on these factors. In addition, the active collaboration of the health system with other social and economic sectors could be an effective policy strategy for reducing socioeconomic inequalities in obesity in adults.
DISCUSSION
ACKNOWLEDGEMENTS
-
CONFLICT OF INTEREST
The authors have no conflicts of interest associated with the material presented in this paper.
Notes
Figure. 1.Concentration curve (CC) of obesity according to socioeconomic status for cohort participants aged 35-65, 2016. The black line is the equality line. The red line below the equality line represents the CC. The father the CC is below the equality line, the more concentrated the health outcome is among the rich.
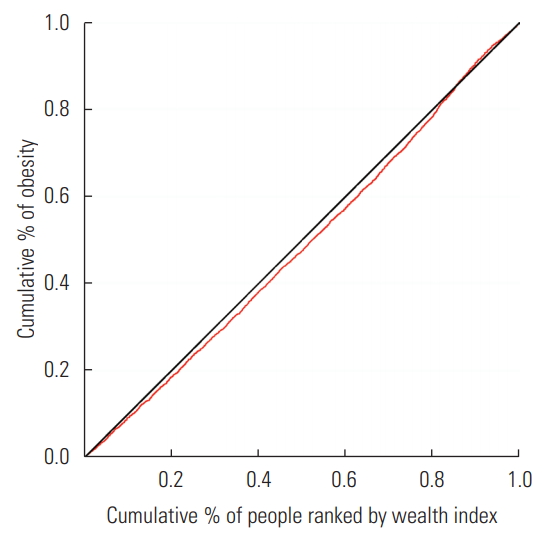
Table 1.Prevalence of obesity in terms of determinant variables among cohort participants aged 35-65, 2016
Table 2.Concentration indices (CIs) of adult obesity
| Sample | n | Normalized CI | Standard error | p-value |
|---|---|---|---|---|
| Total | 10 026 | 0.04 | 0.01 | 0.002 |
| Male | 4626 | 0.10 | 0.02 | <0.001 |
| Female | 5123 | 0.11 | 0.02 | <0.001 |
Table 3.Results for the decomposition of the concentration index of obesity in Kermanshah, 2016
| Variable | Mean | Marginal effect | Elast | Ck | Cont | Adjusted %1 | Sum of adjusted %1 |
|---|---|---|---|---|---|---|---|
| Sex (female) | 0.52 | 0.206 | 0.402 | -0.157 | -0.063 | -51.4 | -51.4 |
| Age (y) | |||||||
| 45-54 | 0.33 | 0.028 | 0.035 | 0.021 | 0.000 | 0.6 | 4.9 |
| 55-65 | 0.23 | -0.026 | -0.023 | -0.229 | 0.005 | 4.3 | - |
| Marital status | |||||||
| Married | 0.90 | 0.096 | 0.322 | 0.036 | 0.011 | 9.4 | 9.4 |
| Socioeconomic status | |||||||
| Second poorest | 0.20 | 0.024 | 0.017 | -0.548 | -0.009 | -7.8 | -7.8 |
| Middle | 0.20 | 0.029 | 0.021 | 0.000 | 0.000 | 0.0 | 0.0 |
| Second richest | 0.20 | 0.052 | 0.038 | 0.548 | 0.021 | 17.1 | 59.2 |
| Richest | 0.20 | 0.064 | 0.047 | 1.090 | 0.052 | 42.1 | - |
| Household size (n) | |||||||
| 3-6 | 0.10 | 0.084 | 0.025 | -0.345 | -0.009 | -7.1 | -7.1 |
| ≥7 | 0.87 | 0.058 | 0.187 | 0.035 | 0.006 | 5.3 | 5.3 |
| Place of residence | |||||||
| Urban | 0.59 | 0.064 | 0.141 | 0.184 | 0.026 | 21.1 | 21.1 |
| Lifestyle factor | |||||||
| Smoking | 0.2 | -0.053 | -0.024 | 0.000 | 0.000 | 0.0 | 0.0 |
| Explained | - | - | - | - | 0.041 | - | - |
| Residuals | - | - | - | - | 0.000 | - | - |
| Total | - | - | - | - | 0.040 | - | 99.9 |
- 1. Alaba O, Chola L. Socioeconomic inequalities in adult obesity prevalence in South Africa: a decomposition analysis. Int J Environ Res Public Health 2014;11(3):3387-3406ArticlePubMedPMC
- 2. Hajizadeh M, Campbell MK, Sarma S. Socioeconomic inequalities in adult obesity risk in Canada: trends and decomposition analyses. Eur J Health Econ 2014;15(2):203-221ArticlePubMed
- 3. Ng M, Fleming T, Robinson M, Thomson B, Graetz N, Margono C, et al. Global, regional, and national prevalence of overweight and obesity in children and adults during 1980-2013: a systematic analysis for the Global Burden of Disease Study 2013. Lancet 2014;384(9945):766-781ArticlePubMedPMC
- 4. Wells JC, Marphatia AA, Cole TJ, McCoy D. Associations of economic and gender inequality with global obesity prevalence: understanding the female excess. Soc Sci Med 2012;75(3):482-490ArticlePubMed
- 5. Little M, Humphries S, Patel K, Dewey C. Factors associated with BMI, underweight, overweight, and obesity among adults in a population of rural south India: a cross-sectional study. BMC Obes 2016;3: 12ArticlePubMedPMC
- 6. World Health Organization. Obesity and overweight. 2018 [cited 2018 Nov 1]. Available from: http://www.who.int/en/news-room/fact-sheets/detail/obesity-and-overweight
- 7. Hajizadeh M, Sia D, Heymann SJ, Nandi A. Socioeconomic inequalities in HIV/AIDS prevalence in sub-Saharan African countries: evidence from the Demographic Health Surveys. Int J Equity Health 2014;13: 18ArticlePubMedPMC
- 8. Jafari-Adli S, Jouyandeh Z, Qorbani M, Soroush A, Larijani B, Hasani-Ranjbar S. Prevalence of obesity and overweight in adults and children in Iran; a systematic review. J Diabetes Metab Disord 2014;13(1):121ArticlePubMedPMCPDF
- 9. Neupane S, Prakash KC, Doku DT. Overweight and obesity among women: analysis of demographic and health survey data from 32 Sub-Saharan African countries. BMC Public Health 2016;16: 30ArticlePubMedPMC
- 10. Dee A, Kearns K, O’Neill C, Sharp L, Staines A, O’Dwyer V, et al. The direct and indirect costs of both overweight and obesity: a systematic review. BMC Res Notes 2014;7: 242ArticlePubMedPMC
- 11. Klarenbach S, Padwal R, Chuck A, Jacobs P. Population-based analysis of obesity and workforce participation. Obesity (Silver Spring) 2006;14(5):920-927ArticlePubMed
- 12. Robroek SJ, van den Berg TI, Plat JF, Burdorf A. The role of obesity and lifestyle behaviours in a productive workforce. Occup Environ Med 2011;68(2):134-139ArticlePubMed
- 13. Janghorbani M, Amini M, Willett WC, Mehdi Gouya M, Delavari A, Alikhani S, et al. First nationwide survey of prevalence of overweight, underweight, and abdominal obesity in Iranian adults. Obesity (Silver Spring) 2007;15(11):2797-2808ArticlePubMed
- 14. Nikooyeh B, Abdollahi Z, Salehi F, Nourisaeidlou S, Hajifaraji M, Zahedirad M, et al. Prevalence of obesity and overweight and its associated factors in urban adults from West Azerbaijan, Iran: the National Food and Nutritional Surveillance Program (NFNSP). Nutr Food Sci Res 2016;3(2):21-26ArticlePDF
- 15. Rahmani A, Sayehmiri K, Asadollahi K, Sarokhani D, Islami F, Sarokhani M. Investigation of the prevalence of obesity in Iran: a systematic review and meta-analysis study. Acta Med Iran 2015;53(10):596-607PubMed
- 16. Pasdar Y, Darbandi M, Niazi P, Alghasi S, Roshanpour F. The prevalence and the affecting factors of obesity in women of Kermanshah. Jorjani Biomed J 2015;3(1):82-97. (Persian)
- 17. Emamian MH, Fateh M, Hosseinpoor AR, Alami A, Fotouhi A. Obesity and its socioeconomic determinants in Iran. Econ Hum Biol 2017;26: 144-150ArticlePubMed
- 18. Mowafi M, Khadr Z, Kawachi I, Subramanian SV, Hill A, Bennett GG. Socioeconomic status and obesity in Cairo, Egypt: a heavy burden for all. J Epidemiol Glob Health 2014;4(1):13-21ArticlePubMed
- 19. Costa-Font J, Gil J. What lies behind socio-economic inequalities in obesity in Spain? A decomposition approach. Food Policy 2008;33(1):61-73Article
- 20. Nikolaou A, Nikolaou D. Income-related inequality in the distribution of obesity among Europeans. J Public Health 2008;16(6):403-411Article
- 21. Djalalinia S, Peykari N, Qorbani M, Larijani B, Farzadfar F. Inequality of obesity and socioeconomic factors in Iran: a systematic review and meta-analyses. Med J Islam Repub Iran 2015;29: 241PubMedPMC
- 22. Poustchi H, Eghtesad S, Kamangar F, Etemadi A, Keshtkar AA, Hekmatdoost A, et al. Prospective epidemiological research studies in Iran (the PERSIAN Cohort Study): rationale, objectives, and design. Am J Epidemiol 2018;187(4):647-655ArticlePubMedPDF
- 23. Rarani MA, Rashidian A, Arab M, Khosravi A, Abbasian E. Inequality in under-five mortality in Iran: a national and subnational survey data analysis. Glob J Health Sci 2016;9(3):215Article
- 24. Liu X, Gao W, Yan H. Measuring and decomposing the inequality of maternal health services utilization in western rural China. BMC Health Serv Res 2014;14: 102ArticlePubMedPMCPDF
- 25. Chalasani S. Understanding wealth-based inequalities in child health in India: a decomposition approach. Soc Sci Med 2012;75(12):2160-2169ArticlePubMed
- 26. Vyas S, Kumaranayake L. Constructing socio-economic status indices: how to use principal components analysis. Health Policy Plan 2006;21(6):459-468ArticlePubMedPDF
- 27. Kjellsson G, Gerdtham UG. On correcting the concentration index for binary variables. J Health Econ 2013;32(3):659-670ArticlePubMed
- 28. Wagstaff A. The bounds of the concentration index when the variable of interest is binary, with an application to immunization inequality. Health Econ 2005;14(4):429-432ArticlePubMed
- 29. Wagstaff A, Paci P, van Doorslaer E. On the measurement of inequalities in health. Soc Sci Med 1991;33(5):545-557ArticlePubMed
- 30. O’Donnell O, van Doorslaer E, Wagstaff A, Lindelow M. Analyzing health equity usinghousehold survey data: a guide to techniques and their implementation. 2008 [cited 2018 Nov 1]. Available from: http://web.worldbank.org/archive/website01411/WEB/IMAGES/HEALTHEQ.PDF
- 31. Erreygers G. Correcting the concentration index. J Health Econ 2009;28(2):504-515ArticlePubMed
- 32. Costa-Font J, Hernández-Quevedo C, Jiménez-Rubio D. Income inequalities in unhealthy life styles in England and Spain. Econ Hum Biol 2014;13: 66-75ArticlePubMed
- 33. Gonzalo-Almorox E, Urbanos-Garrido RM. Decomposing socioeconomic inequalities in leisure-time physical inactivity: the case of Spanish children. Int J Equity Health 2016;15(1):106ArticlePubMedPMC
- 34. Solmi F, Von Wagner C, Kobayashi LC, Raine R, Wardle J, Morris S. Decomposing socio-economic inequality in colorectal cancer screening uptake in England. Soc Sci Med 2015;134: 76-86ArticlePubMed
- 35. Yiengprugsawan V, Lim LL, Carmichael GA, Sidorenko A, Sleigh AC. Measuring and decomposing inequity in self-reported morbidity and self-assessed health in Thailand. Int J Equity Health 2007;6: 23ArticlePubMedPMCPDF
- 36. Wagstaff A, van Doorslaer E, Watanabe N. On decomposing the causes of health sector inequalities with an application to malnutrition inequalities in Vietnam. J Econom 2003;112(1):207-223Article
- 37. Ljungvall A, Gerdtham UG. More equal but heavier: a longitudinal analysis of income-related obesity inequalities in an adult Swedish cohort. Soc Sci Med 2010;70(2):221-231ArticlePubMed
- 38. Hwang J. Decomposing socioeconomic inequalities in the use of preventive eye screening services among individuals with diabetes in Korea. Int J Public Health 2016;61(5):613-620ArticlePubMedPDF
- 39. Kunna R, San Sebastian M, Stewart Williams J. Measurement and decomposition of socioeconomic inequality in single and multimorbidity in older adults in China and Ghana: results from the WHO study on global AGEing and adult health (SAGE). Int J Equity Health 2017;16(1):79ArticlePubMedPMCPDF
- 40. Gwatkin DR, Rutstein S, Johnson K, Suliman E, Wagstaff A, Amouzou A. Socio-economic differences in health, nutrition, and population within developing countries: an overview. 2007 [cited 2018 Nov 1]. Available from: https://siteresources.worldbank.org/INTPAH/Resources/IndicatorsOverview.pdf
REFERENCES
Figure & Data
References
Citations
Citations to this article as recorded by 
- Worse becomes the worst: obesity inequality, its determinants and policy options in Iran
Fatemeh Toorang, Parisa Amiri, Abolghassem Djazayery, Hamed Pouraram, Amirhossein Takian
Frontiers in Public Health.2024;[Epub] CrossRef - Socioeconomic inequality and urban-rural disparity of antenatal care visits in Bangladesh: A trend and decomposition analysis
Biplab Biswas, Nishith Kumar, Md. Matiur Rahaman, Sukanta Das, Md. Aminul Hoque, Benojir Ahammed
PLOS ONE.2024; 19(3): e0301106. CrossRef - Measuring socioeconomic inequalities in postnatal health checks for newborns in Ethiopia: a decomposition analysis
Asebe Hagos, Misganaw Guadie Tiruneh, Kaleab Mesfin Abera, Yawkal Tsega, Abel Endawkie, Wubshet Debebe Negash, Amare Mesfin Workie, Lamrot Yohannes, Mihret Getnet, Nigusu Worku, Adina Yeshambel Belay, Lakew Asmare, Hiwot Tadesse Alemu, Demiss Mulatu Geber
Frontiers in Public Health.2024;[Epub] CrossRef - The Association between Marital Status and Obesity: A Systematic Review and Meta-Analysis
Tamara Nikolic Turnic, Vladimir Jakovljevic, Zulfiya Strizhkova, Nikita Polukhin, Dmitry Ryaboy, Mariia Kartashova, Margarita Korenkova, Valeriia Kolchina, Vladimir Reshetnikov
Diseases.2024; 12(7): 146. CrossRef - Measurement and Decomposition of Socioeconomic Inequality in Metabolic Syndrome: A Cross-sectional Analysis of the RaNCD Cohort Study in the West of Iran
Moslem Soofi, Farid Najafi, Shahin Soltani, Behzad Karamimatin
Journal of Preventive Medicine and Public Health.2023; 56(1): 50. CrossRef - Prevalence of overweight and obesity among Iranian population: a systematic review and meta-analysis
Behnaz Abiri, Amirhossein Ramezani Ahmadi, Shirin Amini, Mojtaba Akbari, Farhad Hosseinpanah, Seyed Ataollah Madinehzad, Mahdi Hejazi, Amirreza Pouladi Rishehri, Alvand Naserghandi, Majid Valizadeh
Journal of Health, Population and Nutrition.2023;[Epub] CrossRef - Association of a pro-inflammatory diet with type 2 diabetes and hypertension: results from the Ravansar non-communicable diseases cohort study
Samira Arbabi Jam, Shahab Rezaeian, Farid Najafi, Behrooz Hamzeh, Ebrahim Shakiba, Mehdi Moradinazar, Mitra Darbandi, Fatemeh Hichi, Sareh Eghtesad, Yahya Pasdar
Archives of Public Health.2022;[Epub] CrossRef - Decomposition of Socioeconomic Inequality in Cardiovascular Disease Prevalence in the Adult Population: A Cohort-based Cross-sectional Study in Northwest Iran
Farhad Pourfarzi, Telma Zahirian Moghadam, Hamed Zandian
Journal of Preventive Medicine and Public Health.2022; 55(3): 297. CrossRef - The socio-economic inequality in body mass index: a PERSIAN cohort-based cross-sectional study on 20,000 Iranian adults
Farhad Pourfarzi, Satar Rezaei, Telma Zahirian Moghadam, Hamed Zandian, Foad Dibazar
BMC Endocrine Disorders.2022;[Epub] CrossRef - Assessing the income-related inequality in obesity among the elderly in China: A decomposition analysis
Jinpeng Xu, Guomei Tian, Ting Zhang, Hongyu Zhang, Jian Liu, Qi Shi, Jiale Sun, Haixin Wang, Bokai Zhang, Qunhong Wu, Zheng Kang
Frontiers in Public Health.2022;[Epub] CrossRef - Socioeconomic disparities in using rehabilitation services among Iranian adults with disabilities: a decomposition analysis
Shahin Soltani, Marzieh Mohammadi Moghadam, Shiva Amani, Shahram Akbari, Amir Shiani, Moslem Soofi
BMC Health Services Research.2022;[Epub] CrossRef - Establishing hematological reference intervals in healthy adults: Ravansar non‐communicable disease cohort study, Iran
Mehdi Moradinazar, Farid Najafi, Yahya Pasdar, Behrooz Hamzeh, Ebrahim Shakiba, Mary Kathryn Bohn, Khosrow Adeli, Zohreh Rahimi
International Journal of Laboratory Hematology.2021; 43(2): 199. CrossRef - Socioeconomic - related inequalities in overweight and obesity: findings from the PERSIAN cohort study
Farid Najafi, Shahin Soltani, Behzad Karami Matin, Ali Kazemi Karyani, Satar Rezaei, Moslem Soofi, Yahya Salimi, Mehdi Moradinazar, Mohammad Hajizadeh, Loghman Barzegar, Yahya Pasdar, Behrooz Hamzeh, Ali Akbar Haghdoost, Reza Malekzadeh, Hossein Poustchi,
BMC Public Health.2020;[Epub] CrossRef - Association of all forms of malnutrition and socioeconomic status, educational level and ethnicity in Colombian children and non-pregnant women
Gustavo Cediel, Eliana Perez, Diego Gaitán, Olga L Sarmiento, Laura Gonzalez
Public Health Nutrition.2020; 23(S1): s51. CrossRef - Türkiye’de Kadınlarda Obezite Üzerine Sosyoekonomik Faktörlerin Etkisi ve Gelir Eşitsizliği
Banu BEYAZ SİPAHİ
Gaziantep University Journal of Social Sciences.2020;[Epub] CrossRef - Socioeconomic inequalities in obesity in Brazil
Lívia Madeira Triaca, Anderson Moreira Aristides dos Santos, Cesar Augusto Oviedo Tejada
Economics & Human Biology.2020; 39: 100906. CrossRef
 PubReader
PubReader ePub Link
ePub Link Cite
Cite- Figure
-

- Related articles
-
- Measurement and Decomposition of Socioeconomic Inequality in Metabolic Syndrome: A Cross-sectional Analysis of the RaNCD Cohort Study in the West of Iran
- Decomposition of Socioeconomic Inequality in Cardiovascular Disease Prevalence in the Adult Population: A Cohort-based Cross-sectional Study in Northwest Iran